【php】根据书名搜索对应封面的API服务
- 2020/09/08
- 0阅读
因为今年的webapp中有个功能需要根据书名搜索封面,但是市面上没有可用的开放API,于是只能自己撸一个了。
因为自己之前没有这方面的经历,同时也没有把这个服务做成怎么怎么高大上的打算。初衷就是一个开发快、查询快的单页面接口。
思路一:通过国家数字图书馆的接口
中国国家数字图书馆 传送门
中国国家数字图书馆中包含了所有印刷出品书籍的副本(之前在“知网事件”中了解到),所以能不能通过调用抓包搜索接口来获取图片的封面呢?
经过测试是可行的,但是有2个缺点:
- 图片不能自定义尺寸,涉及到后期裁切API
- 国家的,风险很大
开发难度:★★★☆☆
开发速度:★★★☆☆
牢饭概率:★★☆☆☆
思路二:通过第三方的开放API平台
试用了几家API提供商,大多是数据不全的。有些近年来很火的玄幻、言情、都市小说根本查不到。
思路三:通过聚合抓取知名小说站点的搜索结果
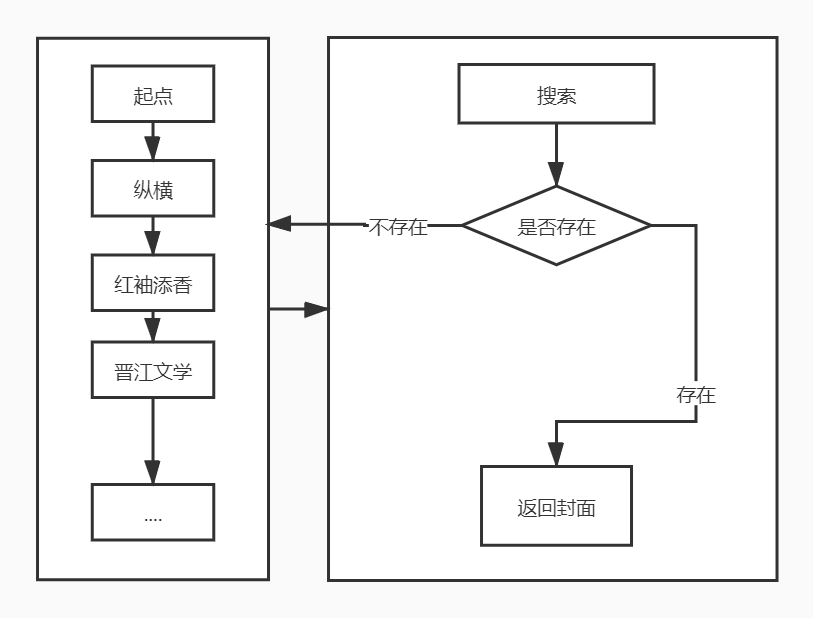
遍历抓取知名小说网站的结果来获取封面。
这个方法存在的缺点是:
- 抓取频率大,浪费时间多
- 后期维护成本高,对应每一个网站都要单独写抓取规则
- 部分站点存在反爬虫机制,抓取难度大
开发难度:★★★★★
开发速度:★☆☆☆☆
牢饭概率:★★★☆☆
思路四:通过搜索引擎的结果来获取
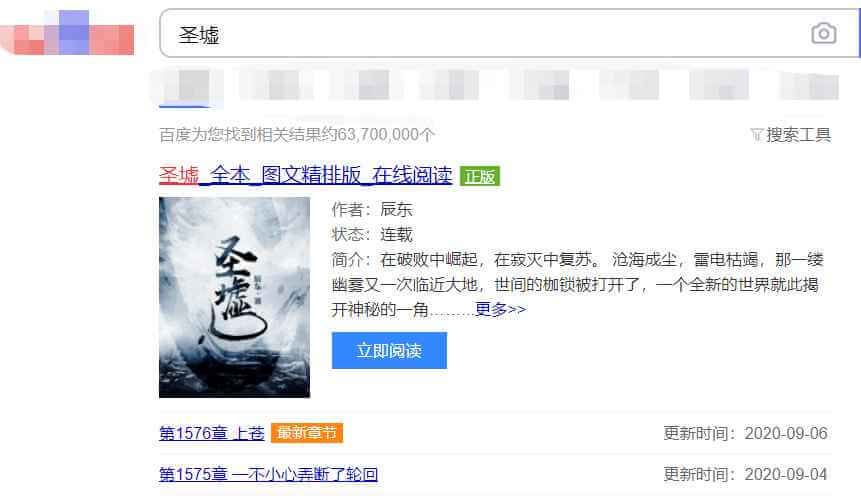
如某搜索引擎的第一条搜索结果会变成该小说的封面,且该图片url地址支持图片处理。即可通过url中的w和h参数来生成对应宽高的封面图,无需在代码中进行图片裁切操作。
使用该方法的好处是:
- 搜索引擎的线路好,查询速度快
- 支持url图片处理,无需再写图片裁切代码
开发难度:★☆☆☆☆
开发速度:★★★★★
牢饭概率:★☆☆☆☆
正式开工
出于某些安全原因考虑,代码就不开源了。这里只说一下几个开发要点
- 首先设置屏蔽错误和允许跨域
1 |
|
- 使用curl来做数据请求
1 | $curl = curl_init(); |
- 使用DOMXPATH类,通过XPATH表达式读取数据
1 | // 阻止因为页面元素不规范引起的报错 |
DOMXPath的用法可以看这里 传送门,主要用到的还是$XPath->query(‘XPath表达式’)。
然后遍历解析DOM元素的属性值,拿到图片url输出即可。
- 网络异常、IP被ban、获取数据失败时的错误处理
关键位置try{}catch($e){},最好设置一个默认返回值用于在异常时返回。
小结
代码量不多,50行左右就完成了一个查询封面服务。同时在代理IP池足够大的情况下完全可以保证高可用。
【php】根据书名搜索对应封面的API服务
作者:有点东西
链接: https://www.youdiandongxi.com/article/search-book-cover.html
协议:本文采用 CC BY-NC-SA 4.0 隐私协议,转载请注明出处!


