微博的采集思路与实现
- 2017/08/30
- 0阅读
2017.12.27更新 今天突然发现不能用了,新浪的api做了改动 多了一个ok和data的字段 读取data即可恢复
昨天帮小徒弟写了一个微博的采集类,乘着中午写篇blog记录下整体实现和思路。
1.网页快照 or html过滤提取
前者需要 CutyCapt的拓展支持(只支持Windows),Linux下需要QT的支持。
这2种拓展都需要依赖于其他的命令或者程序来实现,短期内实现的可能性小,时间不可控。
于是选择采用curl抓取页面,读取html来获取用户动态的采集
2.微博页面读取的尝试
于是尝试使用curl,file_get_contents去读取页面,先解决了读取https的小问题(一定要开启php_openssl)
当解决了https的问题后,我才发现微博的页面居然是动态生成的,于是开启console去寻找微博对应的接口
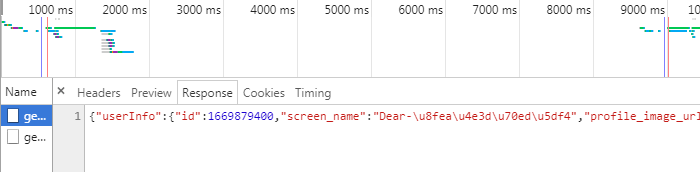
(省略寻找的过程… )
图上的2个ajax分别为用户的基本信息和用户的动态信息
因为采集时需要知道用户的uid,所以直接拿着uid先请求第一个接口
之所以要先请求第一接口而不是直接请求第二个,是因为第二个接口访问需要一个containerid(也可以理解为用户的访问密匙)
拿着第一个请求中的访问密匙访问第二个接口就能获取到该用户的微博动态。
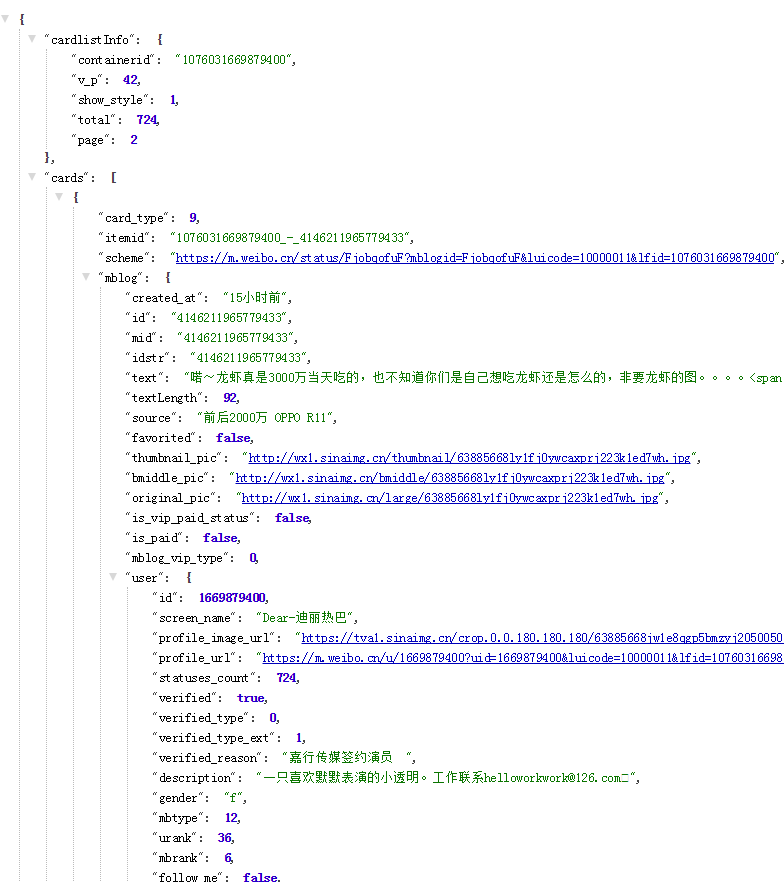
同时在url结尾加上&page=n即可获取第N页的动态
到此整个采集的思路和实现已经讲完了,之后只需要加2个cron Job,定时抓取用户的动态即可。

微博的采集思路与实现
作者:有点东西
链接: https://www.youdiandongxi.com/article/weibo-catch.html
协议:本文采用 CC BY-NC-SA 4.0 隐私协议,转载请注明出处!


