在Hexo中支持语雀的高亮块和折叠块功能(2024/9/26更新)
- 2024/09/23
- 0阅读
一、原始效果
首先我们需要了解2个功能项的markdown输出内容,在语雀文档中创建1个高亮块和折叠块,随便输入一些内容并导出为md文档。
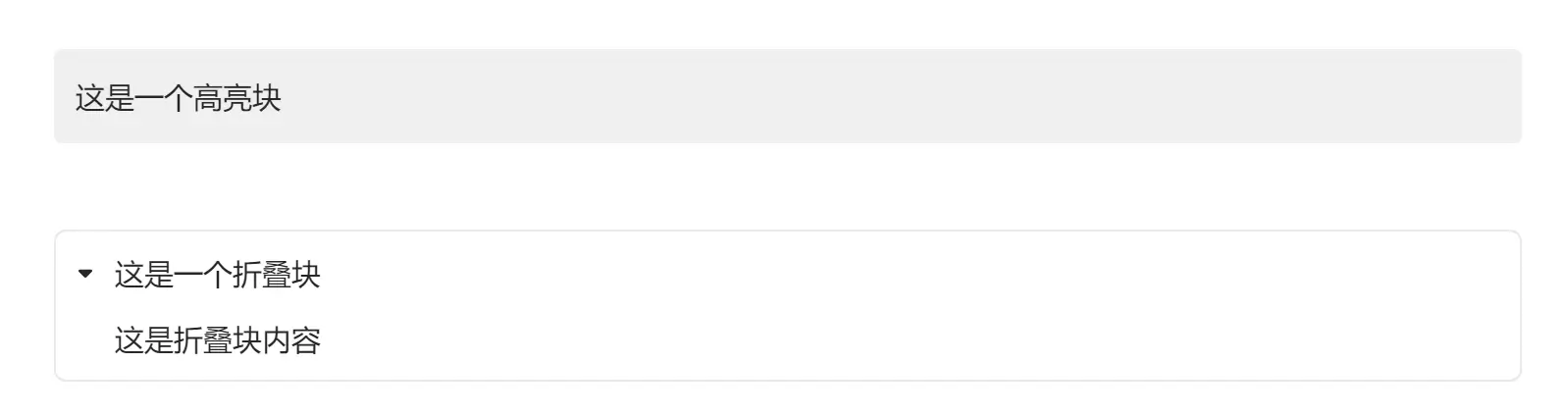
在源码中我们可以看到对于高亮块是使用:::包裹的,不同的颜色是以:::后的英文名称,如tips、info、success、color1等区分的;而折叠块则是使用原生的html标签(details、summary)构成的。
1 | :::tips |
运行Hexo,在界面中看到的效果如下:

二、折叠块样式美化
折叠块使用的details标签是HTML原生支持的,不需要JS脚本就可以完成折叠/展开的效果,我们只需要使用CSS美化下结构样式即可。这个最简单,我们先整这个!
就让ChatGPT生成一套details基础样式,然后我们再针对主题色进行微调就完成了。
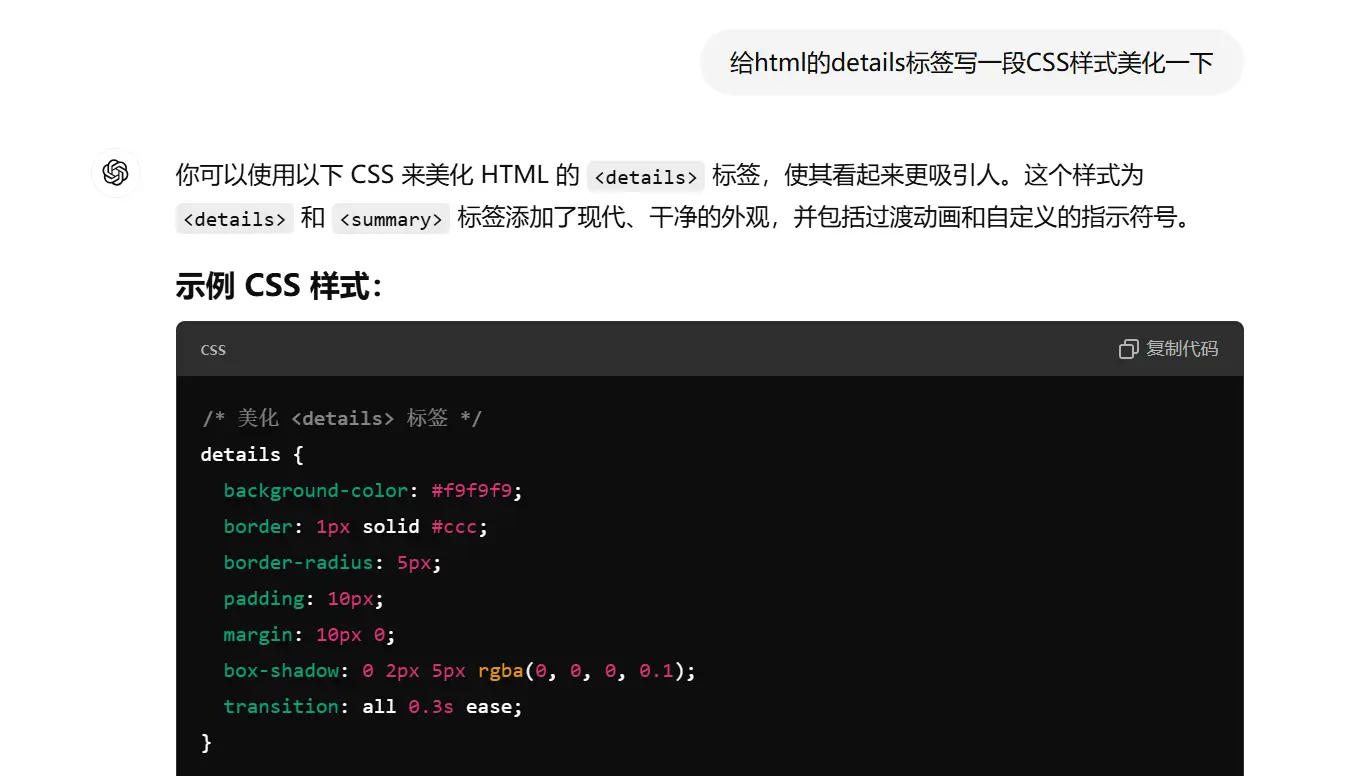
分享一下Blog使用details样式,可以根据自己的需要再微调:
1 | /** |
另外,也许你会发现在details、summary等标签中存在无用的class、id属性字段。我们可以创建一个自定义过滤器来清除它们:
1 | hexo.extend.filter.register('before_post_render', function(data) { |
filter并不会修改md文件内容,仅在hexo页面渲染、构建时进行处理,这就会导致处理时资源重复消耗。最好能够在md文件创建时就对无用属性内容进行过滤,这样只需要处理一次!
三、高亮块样式渲染
由于高亮块内容用了特定的:::进行包裹,所以我们可以借助hexo.extend.filter.register构建自己的过滤器方法。在开始前只需要准备好一个正则匹配表达式即可(当然,这个工作也可以交给ChatGPT!)。
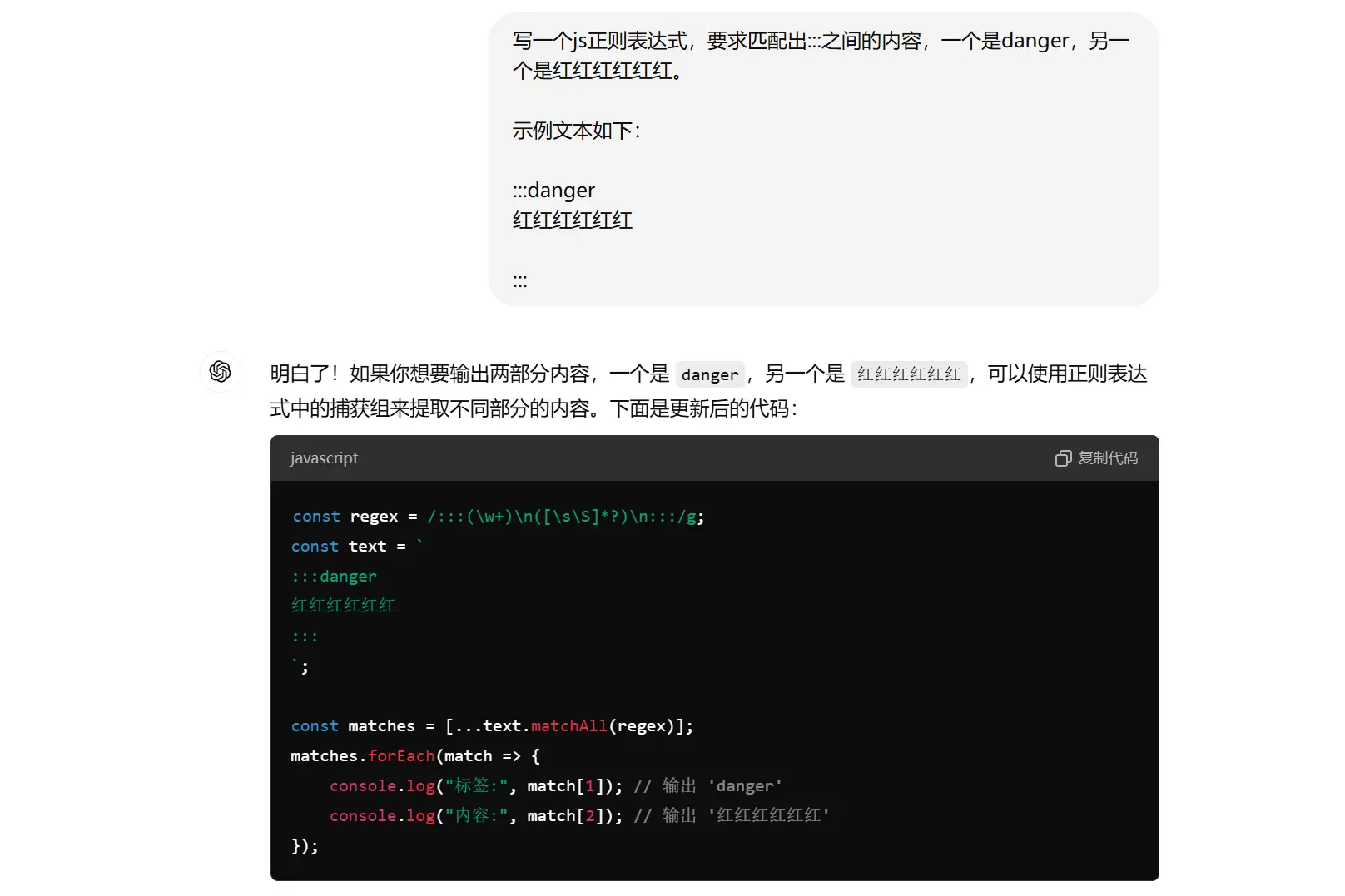
现在我们可以构建自己的过滤器了,代码如下:
1 | hexo.extend.filter.register('before_post_render', function(data) { |
四、效果演示
这是Blog第一个高亮块
这是Blog第一个折叠块
Hello World!
五、BUG修复(2024/9/26更新)
在支持这两个功能后,我最新的游记《大连行:海水是什么颜色的?》已经使用上了高亮块。但我发现存在2个问题:
- markdown的高亮效果丢失;
- 存在多行内容时,首行以后的内容不会出现在高亮块中;
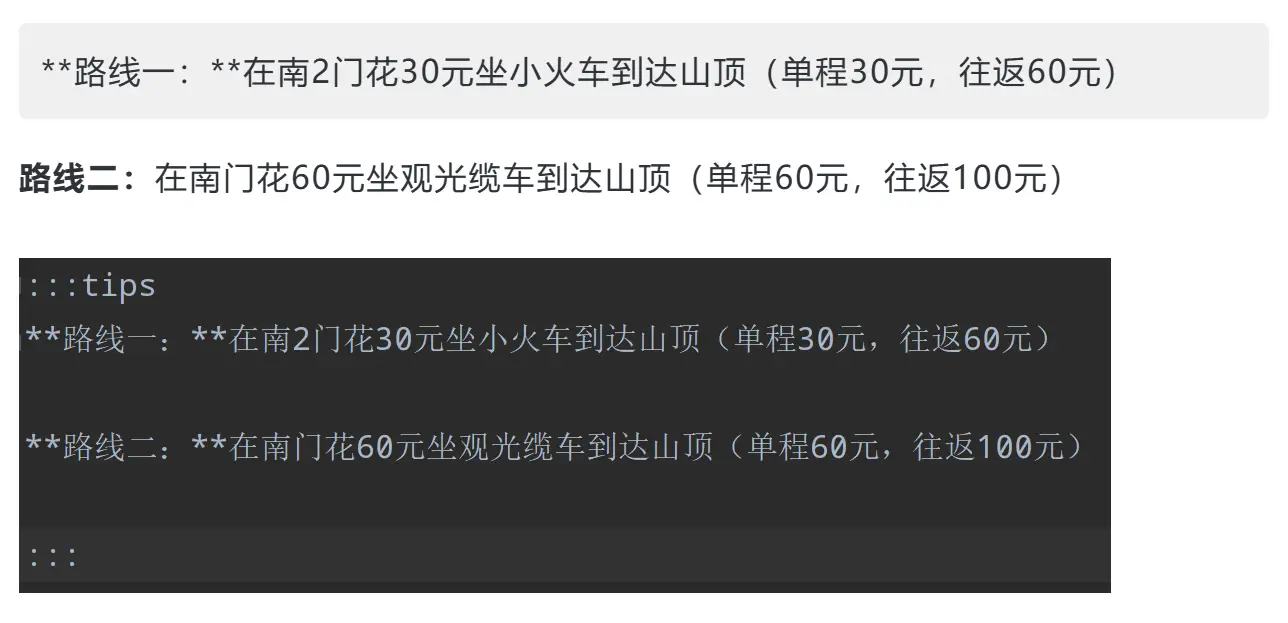
5.1 markdown的高亮效果丢失
原因是因为在拓展是在before_post_render钩子处运行的,而hexo的渲染顺序是这样的:
- 执行
before_post_render过滤器 - 使用 Markdown 或其他渲染器渲染(根据扩展名而定)
- 使用Nunjucks渲染
- 执行
after_post_render过滤器
这使得过滤器运行完毕后,Markdown渲染器未能正确的进行内容渲染(hexo默认渲染器似乎不会对html标签内的内容进行处理)。那就意味着我们需要手动进行内容的markdown渲染了!
1 | hexo.extend.filter.register('before_post_render', function(data) { |
5.2 存在多行内容时,首行以后的内容不会出现在高亮块中
这个问题主要是下面这行代码导致的:
1 | // 源代码 |
在Hexo中每一行文本会被渲染为<p>文本...</p>。这就导致多行内容会出现<p>标签嵌套的情况。而<p>标签嵌套是不符合HTML规范的,浏览器会自动转换第二种形式。
1 | <!-- 生成的html --> |
所以改动也很简单,将最外层的<p>标签改为<div>标签即可!
1 | // old |
在Hexo中支持语雀的高亮块和折叠块功能(2024/9/26更新)
作者:有点东西
链接: https://www.youdiandongxi.com/article/hexo-support-highlight-and-fold-block.html
协议:本文采用 CC BY-NC-SA 4.0 隐私协议,转载请注明出处!

