[长文]将语雀文档内容同步Hexo
- 2024/09/15
- 0阅读
一、背景
在去年将Blog迁移到Hexo之前,我已经使用了一年多的语雀。最初使用语雀是为了编写公司内部的前端知识库(多人协同支持较好、文档编辑功能比较丰富、还集成了基础的用户权限),后来发现文档可以导出markdown形式,甚至可以通过付费会员的API功能获取及修改文档内容。从这时候开始,我就在想既然能从Typecho迁移到Hexo,那应该也可以从语雀拉取内容至Hexo。
我在之前的文章《Hexo迁移记录》中提到过当时写了一个Typecho迁移工具,原理是从feed.xml文件中读取文章的html结构内容,通过turndown将html转换为markdown格式内容。而现在语雀的API是可以直接返回markdown的。
这意味着同步语雀文档内容时,可以忽略掉markdown转换的步骤。只需要考虑如何从markdown中提取图片下载到本地即可!
二、思路
结合之前Typecho迁移的经验,又查阅了语雀API返回格式后,我感觉这个事可行性非常大。于是梳理了一下流程步骤,大致如下:
- 执行命令行指令,输入语雀文档URL
- 调用API接口,获取语雀文档内容
- 创建Hexo文档,导入语雀文档内容
- 解析文档内容,读取图片URL
- 下载图片至附件文件夹
- 对文档中的图片引用信息进行替换
整个步骤看起来还是比较简单的。
三、尝试
下面就根据上述步骤,逐个讲解下实践过程。
3.1 执行命令行指令,输入语雀文档URL
参考官方教程先创建对应的命令行指令,增加一个参数来接收语雀文档URL。
1 | hexo.extend.console.register('sync', 'Sync yuque markdown to Hexo', { |
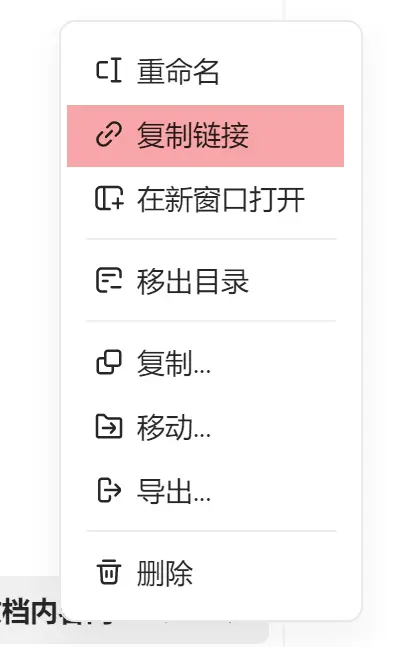
右键文档 - 复制链接就可以获取到语雀文档URL,格式长这样:https://www.yuque.com/[用户名]/[book_id]/[id]。
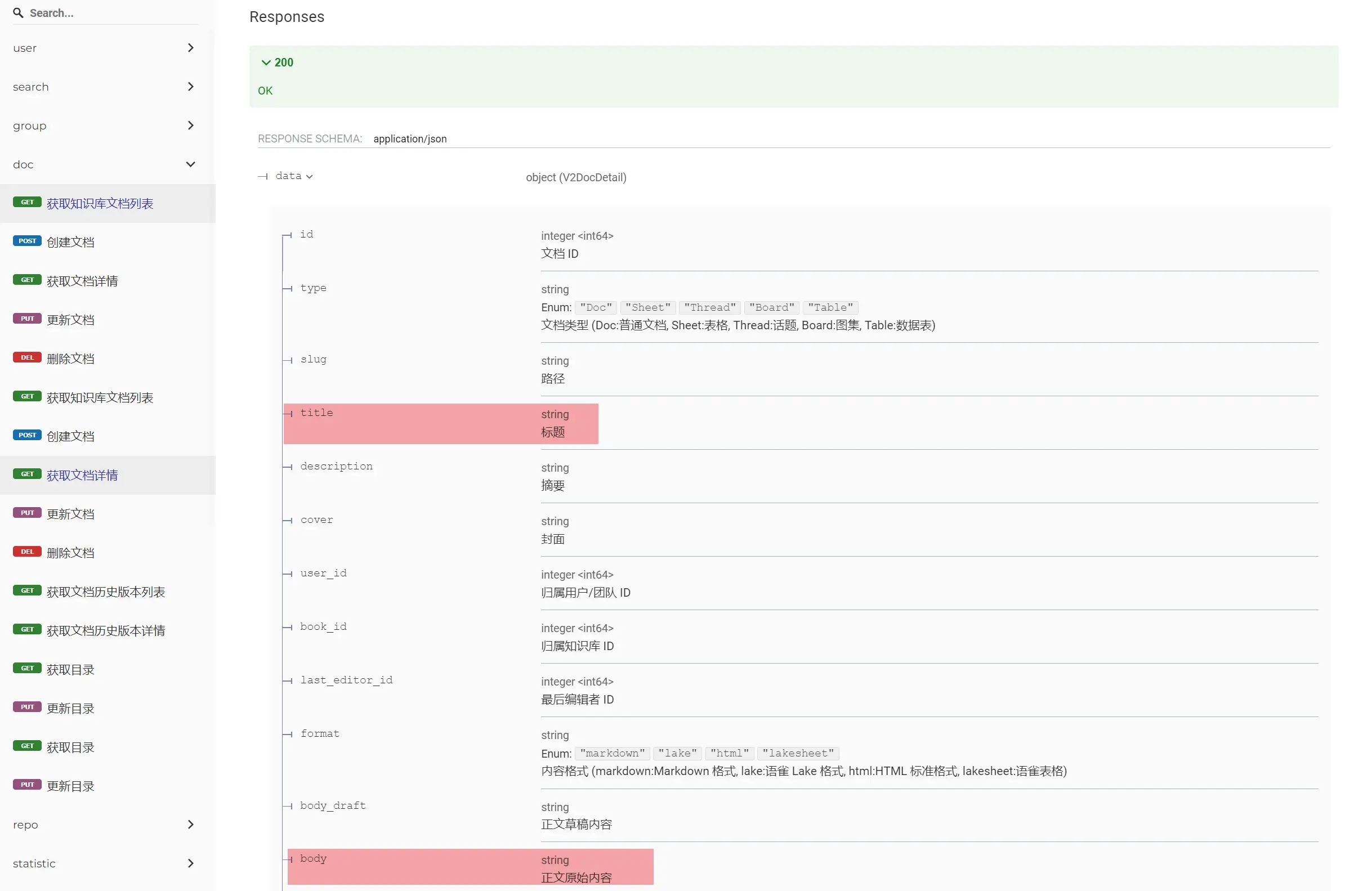
3.2 调用API接口,获取语雀文档内容
注意:本步骤如果之前没有创建过语雀Personal Access Token,则需要开通语雀超级会员(¥299)!
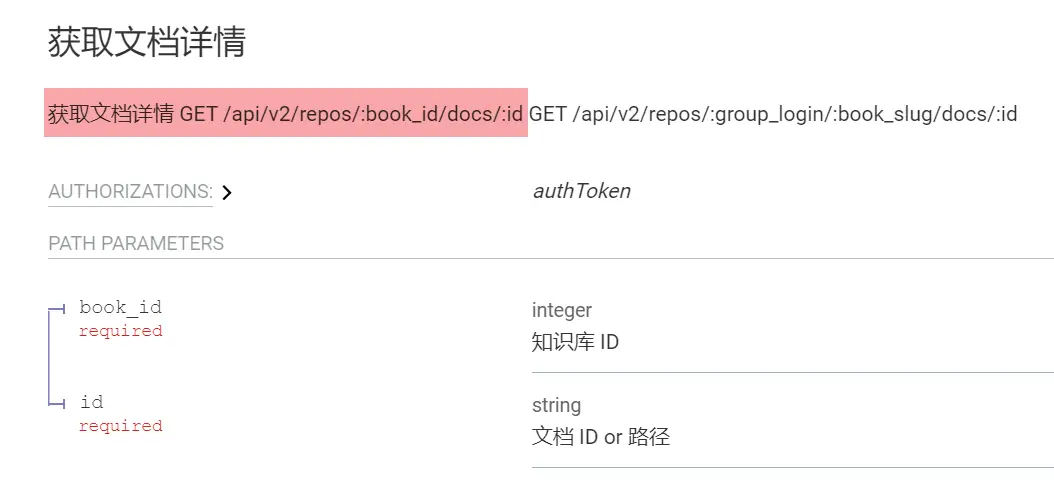
在语雀官方文档下载接口文档,找到需要使用的接口。

主要用到“获取文档详情”这个接口,之后用fetch或者axios库发送请求获取数据即可。
3.3 创建Hexo文档,导入语雀文档内容
借助hexo.post.create这个方法,我们可以快速的构建文档文件和对应的文档附件文件夹。
1 | hexo.post.create({ |
为什么是先创建Hexo文档,而不是全部处理完后一次性创建呢?
最初设想是一次性处理完再创建,但之后实践发现对于文档图片的下载存储会比较麻烦,不如借助hexo.post.create先将文档、附件文件夹创建好,之后再把图片下载到对应目录会更方便。
3.4 解析文档内容,读取图片URL
和之前迁移Typecho文章图片不同的是,之前可以通过cheerio读取html中的img标签来获取图片地址,现在body中是markdown形式的内容,需要通过正则表达式匹配图片信息,这会稍微麻烦一些。
1 | // markdown图片的正则匹配表达式 |
3.5 下载图片至附件文件夹
借助axios以流形式下载图片文件,防止图片过大导致出现问题。附件文件夹则可以通过hexo.source_dir来获取资源文件夹目录,再根据post_asset_folder来调整拼接图片文件夹目录。
1 | const url = '图片URL地址' |
个人是非常推荐启用
post_asset_folder的,这样不同文章的图片会放到与该文档同名的目录中,后期寻找对应关系也方便不少。
3.6 对文档中的图片引用信息进行替换
对markdown正文内容进行替换,将图片的链接部分调整为本地图片链接后,再执行一次hexo.post.create就可以更新文档了(该操作不会影响附件文件夹,可以放心操作)。
1 | // 进行图片引用替换 |
四、问题
4.1 拉取的文档内容中存在大量的锚点标签
可以通过以下的正则表达式在第三步之前进行替换过滤
1 | const linkRegex = /<a\s+.*?name="(.*?)".*?>(.*?)<\/a>/g |
4.2 “_”在转换后会变成”-“
hexo通过hexo-util的slugize函数来对slug进行处理,在函数方法的第四行中可以看到默认的分隔符是-。如果设置的slug以_分隔,就会导致图片下载失败(因为生产的文档slug和附件文件夹名称会变成-,导致图片找不到存储目录)。
1 | function slugize(str: string, options: Options = {}) { |
4.3 一部分语雀功能无法转换成markdown形式
是的,有一部分功能以html标签或者图片形式存在,另一部分无法正常处理。有关于语雀功能转换的支持情况请见第六段:兼容性。
五、拓展
在成功拉取语雀文档后,我又给命令行增加了2个参数来设定分类和文档名称。
1 | hexo.extend.console.register('sync', 'Sync yuque markdown to Hexo', { |
现在通过一行命令hexo sync https://www.yuque.com/***** -c 分类 -s 路径名称即可完从语雀文档同步到Hexo的功能。
六、兼容性
6.1 编辑功能
在基础编译功能上,语雀的转换形式进步了不少。去年测试时,上标、字体颜色、背景颜色等功能还无法在hexo中显示出来,今年都以html标签加带行内样式的形式支持了。对于现有的18项编辑功能markdown支持率达到了77%。
| 功能点 | 是否支持 | 备注 |
|---|---|---|
| 正文与标题 | ✔ | |
| 字体大小 | ❌ | |
| 加粗 | ✔ | |
| 斜体 | ✔ | |
| 删除线 | ✔ | |
| 下划线 | ✔ | 输出u标签形式 |
| 上标 | ✔ | 输出sup标签形式 |
| 下标 | ✔ | 输出sub标签形式 |
| 行内代码 | ✔ | |
| 字体颜色 | ✔ | 输出带颜色的font标签形式 |
| 背景颜色 | ✔ | 输出带背景颜色的font标签形式 |
| 对齐方式 | ❌ | |
| 无序列表 | ✔ | |
| 有序列表 | ✔ | |
| 缩进 | ❌ | |
| 行高 | ❌ | |
| 任务列表 | ✔ | |
| 链接 | ✔ |
6.2 拓展功能
另外,经过我对语雀其他27个功能点的转换测试,其中有10个功能点能够较好的在hexo中呈现,有3个功能点的样式展示存在一定问题,剩余14个则完全不支持在Hexo中显示(需要前往语雀页面查看)。下面是具体的转换情况:
| 功能点 | 是否支持 | 备注 |
|---|---|---|
| 基础 | ||
| ▷ 图片 | ✔ | |
| ▷ 附件 | ❌ | 输出超链接,需要跳转到语雀登录查看 |
| ▷ 状态 | ✔ | 输出带背景色的font标签(样式需要自行适配) |
| 画板类 | ||
| ▷ 画板 | ✔ | 以图片形式输出 |
| ▷ 思维导图 | ❌ | 未输出内容 |
| ▷ 流程图 | ❌ | 未输出内容 |
| 数据表 | ||
| ▷ 数据表 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
| ▷ 画册 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
| ▷ 看板 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
| 程序员专区 | ||
| ▷ 代码块 | ✔ | |
| ▷ 公式 | ✔ | 以图片形式输出 |
| ▷ UML图 | ✔ | 以图片形式输出 |
| ▷ 文本绘画 | ✔ | 以图片形式输出 |
| 布局和样式 | ||
| ▷ 高亮块 | ⚠️ | 输出:::格式无法在hexo中转换显示 |
| ▷ 折叠块 | ⚠️ | 输出了details标签(样式需要自行适配) |
| ▷ 分栏卡片 | ❌ | 没有输出任何样式或者标签,无法特殊处理 |
| ▷ 引用 | ✔ | 支持 |
| ▷ 插入分割线 | ✔ | 输出hr标签(样式需要自行适配) |
| ▷ 表情 | ✔ | 输出emoji表情 |
| ▷ 图册 | ❌ | 没有输出任何样式或者标签,无法特殊处理 |
| 小工具 | ||
| ▷ 提及 | ❌ | 输出的超链接有误 |
| ▷ 语雀内容 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
| ▷ 日历 | ❌ | 未输出内容 |
| ▷ 日期 | ⚠️ | 输出了日期,但是没有任何样式或者标签,无法特殊处理 |
| ▷ 投票 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
| ▷ 打卡 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
| ▷ 加密文本 | ❌ | 输出语雀卡片,需要跳转到语雀登录查看 |
总的来说,目前语雀文档markdown转换效果对于日常的Blog编写已经足够了。后续我会再研究下高亮块、折叠块的兼容方式,至少这两个功能有输出特定的格式,还有可能通过编写自定义的Hexo过滤器(filter)来进行效果支持。
七、结尾
从去年迁移到现在已经快一年了,最初选择Hexo是因为它可以生成静态网站,不需要配置数据库、运行环境等一堆东西,部署网站也极其简单,哪怕扔到OSS、Github Pages也能运行。现在回过头看当时的选择是无比正确的,毕竟越简单到最后就越稳定。
[长文]将语雀文档内容同步Hexo
作者:有点东西
链接: https://www.youdiandongxi.com/article/hexo-synchronize-from-yuque.html
协议:本文采用 CC BY-NC-SA 4.0 隐私协议,转载请注明出处!

