一、背景 去年开发的《个人数据管理中台》项目最初选定的数据库是 Sqlite (轻便的单文件数据库,感觉特别适合个人桌面端项目使用),后面改用 MySQL 主要是因为Sqlite不支持数据库文件加密 ,并且过去使用PHP开发全栈时有一定的Mysql使用经验。
当时放弃Sqlite主要原因就是没法进行数据库加密
转折点来自上个月,在搜索其他问题时看到一个支持加密的Sqlite变种数据库——Turso 之前的文章 中已经通过 Drizzle ORM 在Nuxt中成功集成了Turso本地数据库。在开始前,我查阅了 Prisma 的官方文档,确认 Prisma 支持连接Turso本地数据库。
Prisma支持链接Turso
另外在迁移过程中,我还遇到了一个核心问题:Prisma ORM默认不兼容Turso的加密机制 ,导致数据库通过适配器可以连接成功 数据库迁移、数据结构变更无法使用 无法初始化Turso本地加密数据库 Drizzle ORM 的迁移经历,我终于找到了解决方案。本文详细记录了整个迁移流程,从迁移前准备、核心步骤,到表结构迁移与后续表结构变动时的处理方式。希望能给有同样集成Turso的开发者提供一些参考。
二、预期效果 由于Turso加密后的数据库无法使用常规的数据库工具读取,开发过程中又不免需要查库调试,所以我打算配置两套环境:
Dev环境:未使用encryptionKey配置的标准数据库(SQLite),可以通过常规数据库工具进行访问。
Prod环境:使用encryptionKey配置的加密数据库(Turso),只能通过Prisma适配器或者Turso Cli工具访问。
在此基础上,解决 Prisma 针对 Turso 不支持数据迁移、数据导入的问题,并最终完成 Dev、Prod 环境的历史数据同步以及未来开发过程中的数据结构同步需求。
三、迁移前准备
由于之前验证 Drizzle ORM 集成时用得是新建的Nuxt4项目,所以本次迁移前我先把项目依赖更新到最新;
安装 Prisma 适配器@prisma/adapter-libsql和 Turso 本地客户端@libsql/client;
1 2 npm install @prisma/adapter-libsql npm install @libsql/client
安装dotenv-cli适配自定义脚本及多环境开发(如dev环境关闭加密数据库功能,prod环境启用加密数据库);
1 npm install --save-dev dotenv-cli
有人可能会疑惑:Nuxt 本身已经内置了 dotenv,并且会自动读取 .env 中的环境变量,为什么我们还要额外安装一次 dotenv?
原因很简单:后续编写自定义 Node.js 脚本时,仍需要独立读取本地配置文件,这一步安装是为了给这些脚本使用。
最后,必要得依赖项如下:
package.json 1 2 3 4 5 6 7 8 9 10 11 12 { "dependencies" : { "@libsql/client" : "^0.17.2" , "@prisma/adapter-libsql" : "^7.6.0" , "@prisma/client" : "^7.6.0" } , "devDependencies" : { "dotenv-cli" : "^11.0.0" , "nuxt" : "^4.4.2" , "prisma" : "^7.6.0" } }
四、开始迁移 (1)修改 Prisma配置 从 v7 版本开始,需要创建 prisma.config.ts来进行 Prisma 配置,先创建配置文件:(为了便于管理,我把 Prisma 的文件都放置在./prisma/目录下)
prisma.config.ts 1 2 3 4 5 6 7 8 9 10 11 12 import "dotenv/config" ;import { defineConfig } from "prisma/config" ;export default defineConfig ({ schema : "prisma/schema.prisma" , migrations : { path : "prisma/migrations" , }, datasource : { url : process.env ["DATABASE_URL" ], }, });
修改.env.*环境变量文件:
.env 1 2 3 4 5 6 7 DATABASE_URL=file:./prisma/database/dev.db TURSO_AUTH_TOKEN= TURSO_ENCRYPTION_KEY=
修改 schema.prisma文件,将数据库驱动调整为sqlite:
schema.prisma 1 2 3 4 5 6 7 8 generator client { provider = "prisma-client" // 从 prisma-client-js 改为 prisma-client output = "../prisma/generate" } datasource db { provider = "sqlite" // 从 mysql 改为 sqlite }
(2)根据 schema.prisma 文件生成 Turso 数据库文件 调整package.json,增加数据库迁移命令:
package.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 { "scripts" : { "dev:migrate" : "npx prisma migrate dev" , "prod:migrate" : "dotenv -e .env.production -- node prisma/migrate.ts" } , "dependencies" : { "@libsql/client" : "^0.17.2" , "@prisma/adapter-libsql" : "^7.6.0" , "@prisma/client" : "^7.6.0" } , "devDependencies" : { "dotenv-cli" : "^11.0.0" , "nuxt" : "^4.4.2" , "prisma" : "^7.6.0" } }
现在开发环境因为是未加密的 Sqlite 数据库,所以 Prisma 可以自己执行迁移过程;而生产环境则需要我们自己处理迁移过程了。
处理加密数据库的表结构迁移过程和之前处理 Drizzle ORM 的方式有所不同,我改用 Prisma 官方推荐的 prisma migrate diff 命令来处理迁移过程。生产环境的迁移思路如下:
通过prisma migrate diff --script > migration.sql生产迁移脚本
使用@libsql/client连接加密数据库
执行生成的migration.sql数据库脚本
prisma/migrate.ts 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 import { createClient } from '@libsql/client' ;import { execSync } from 'child_process' ;import fs from 'fs' ;async function runMigration ( const encryptionKey = process.env .TURSO_ENCRYPTION_KEY ; const targetDbUrl = process.env .DATABASE_URL !; const schemaPath = "./prisma/schema.prisma" ; const command = `npx prisma migrate diff --from-empty --to-schema ${schemaPath} --script > migration.sql` ; try { execSync (command); const sql = fs.readFileSync ('migration.sql' , 'utf8' ); const client = createClient ({ url : targetDbUrl, encryptionKey : encryptionKey }); await client.execute (createMigrationsTableSql); await client.close (); } catch (e) { console .error ("迁移失败:" , e); } } runMigration ();
注意:
默认生成的表结构迁移脚本中,不包含_prisma_migrations表结构,需要手动编写脚本将其插入!
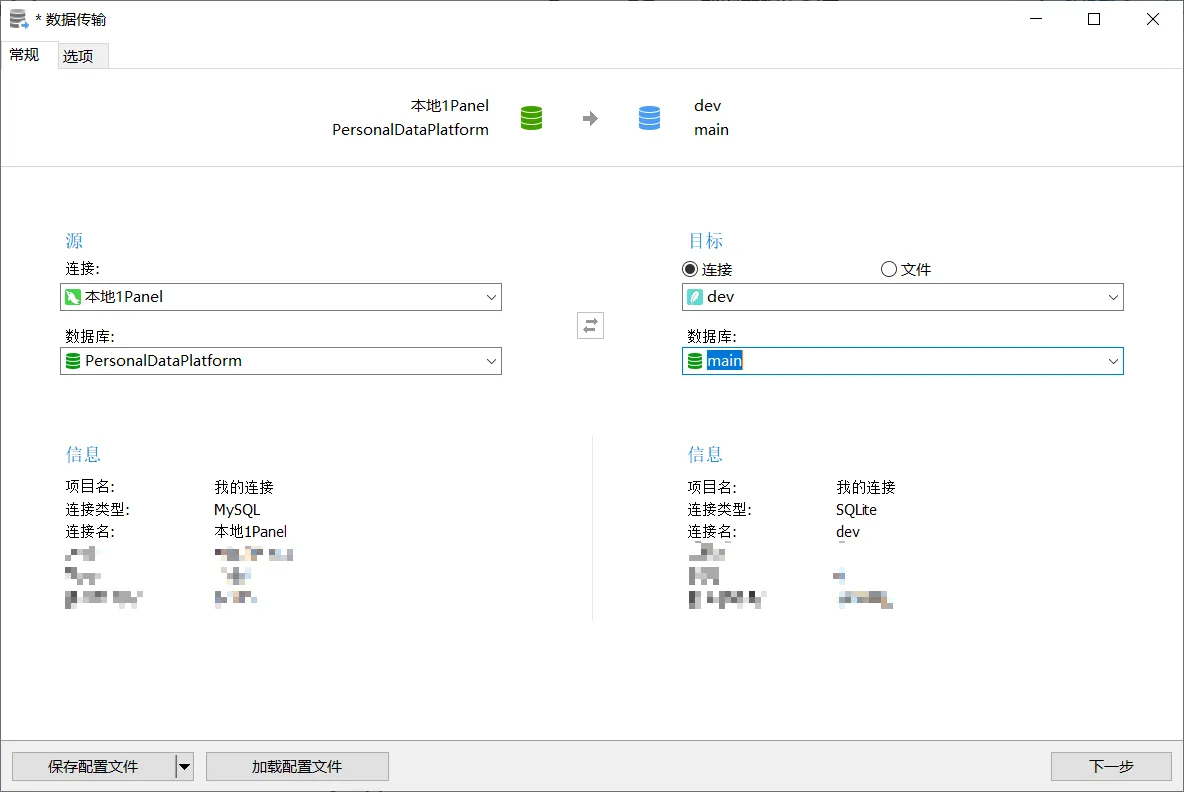
(3)同步Mysql数据库记录至开发环境 这里为了方便和保证数据完整性,我直接用专业数据库工具 Navicat 的数据传输功能来同步数据。
顶部工具栏 - 工具 - 数据传输
在左侧选好源数据库 ,右侧选择目标数据库 ,然后点击右下方的 下一步 即可。
通过数据传输功能进行数据同步
在package.json中补充启动命令 ,并验证开发环境运行正常。
package.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 { "scripts" : { "dev:migrate" : "npx prisma migrate dev" , "prod:migrate" : "dotenv -e .env.production -- node prisma/migrate.ts" , "dev:serve" : "nuxt dev --host" , "prod:serve" : "nuxt dev --host --dotenv .env.production" } , "dependencies" : { "@libsql/client" : "^0.17.2" , "@prisma/adapter-libsql" : "^7.6.0" , "@prisma/client" : "^7.6.0" } , "devDependencies" : { "dotenv-cli" : "^11.0.0" , "nuxt" : "^4.4.2" , "prisma" : "^7.6.0" } }
(4) 同步开发环境数据至生产环境 因为生产环境的数据库是加密后的 Turso 数据库,而 Navicat 到目前为止并不支持 Turso,所以只能自己编写脚本进行数据同步工作,这一步新增了5条命令:
package.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 { "scripts" : { "dev:migrate" : "npx prisma migrate dev" , "dev:export" : "dotenv -e .env -- node prisma/export.ts" , "dev:import" : "dotenv -e .env -- node prisma/import.ts" , "prod:migrate" : "dotenv -e .env.production -- node prisma/migrate.ts" , "prod:export" : "dotenv -e .env.production -- node prisma/export.ts" , "prod:import" : "dotenv -e .env.production -- node prisma/import.ts" , "prod:sync" : "dotenv -e .env.production -- node prisma/sync.ts" } , "dependencies" : { "@libsql/client" : "^0.17.2" , "@prisma/adapter-libsql" : "^7.6.0" , "@prisma/client" : "^7.6.0" } , "devDependencies" : { "dotenv-cli" : "^11.0.0" , "nuxt" : "^4.4.2" , "prisma" : "^7.6.0" } }
prisma/export.ts负责导出数据库中的数据至*.sql文件,用于其他环境的导入工作。
prisma/export.ts 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 import { createClient } from '@libsql/client' ;import * as fs from 'fs' ;import * as path from 'path' ;async function runExport ( const dbUrl =process.env .DATABASE_URL !; const authToken = process.env .TURSO_AUTH_TOKEN ; const encryptionKey = process.env .TURSO_ENCRYPTION_KEY ; const dbName = path.basename (dbUrl) const outputFile = `./prisma/backup/backup_${dbName} _${new Date ().getTime()} .sql` ; const client = createClient ({ url : dbUrl, authToken, encryptionKey }); try { const masterResult = await client.execute ( "SELECT type, name, sql FROM sqlite_master WHERE name NOT LIKE 'sqlite_%' AND sql IS NOT NULL" ); let sqlDump = `-- Database Dump (${dbName} )\n-- Generated at: ${new Date ().toLocaleString()} \n` ; sqlDump += "PRAGMA foreign_keys=OFF;\n" ; for (const row of masterResult.rows ) { const type = row.type as string ; const name = row.name as string ; const sql = row.sql as string ; sqlDump += `\n-- ${type .toUpperCase()} : ${name} \n` ; sqlDump += `DROP ${type .toUpperCase()} IF EXISTS "${name} ";\n` ; sqlDump += `${sql} ;\n` ; if (type === 'table' ) { const dataResult = await client.execute (`SELECT * FROM "${name} "` ); for (const dataRow of dataResult.rows ) { const keys = Object .keys (dataRow); const columns = keys.map (k =>`"${k} "` ).join (', ' ); const values = Object .values (dataRow).map (v => if (v === null ) return 'NULL' ; if (typeof v === 'string' ) { return "'" + v.replace (/'/g , "''" ) + "'" ; } return v; }).join (', ' ); sqlDump += `INSERT INTO "${name} " (${columns} ) VALUES (${values} );\n` ; } } } sqlDump += "\nPRAGMA foreign_keys=ON;" ; fs.writeFileSync (outputFile, sqlDump); } catch (error : any ) { console .error ("导出失败:" , error.message ); } finally { client.close (); } } runExport ();
prisma/import.ts执行的命令形式为npm run dev:import <file_path>,负责导入指定路径下的*.sql文件至数据库。
prisma/import.ts 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import { createClient } from '@libsql/client' ;import * as fs from 'fs' ;import * as path from 'path' ;import * as readline from 'readline' ;async function runImport ( const filePath = process.argv [2 ]; const dbUrl =process.env .DATABASE_URL !; const authToken = process.env .TURSO_AUTH_TOKEN ; const encryptionKey = process.env .TURSO_ENCRYPTION_KEY ; const dbName = path.basename (dbUrl) const client = createClient ({ url : dbUrl, authToken, encryptionKey }); try { const sqlContent = fs.readFileSync (filePath, 'utf8' ); await client.execute ("PRAGMA foreign_keys = OFF;" ); await client.executeMultiple (sqlContent); await client.execute ("PRAGMA foreign_keys = ON;" ); } catch (error : any ) { console .error (`导入失败: ${error.message} ` ); } finally { client.close (); } } runImport ();
最后,我根据编写的三个命令组合实现了两种同步方式:
全量同步 :通过环境:export、环境:import命令,导入导出整个数据库表结构和记录,并进行完整的重建写入,适用于表结构发生变动后 的同步数据场景。增量同步 :通过prod:sync命令,遍历开发环境 的所有数据表,对生产环境 的每张表的记录进行插入或覆盖,适用于表结构未发生变动 ,仅同步数据的场景。
以上只是简略演示,主包后面还做了不少优化,如增加了额外的边界检查 和导入导出前备份、二次确认 等策略,大家根据自己的需求去完善即可。
后续数据验证的过程这里就不放了,主包是写了一个脚本依次读取全部表的全部数据,对比两个数据库下的记录内容是否一致(因为主包的现有数据量不大,所以这样操作还是比较方便和简单的)。
五、开发时的表结构变动 还有一种常见的场景是:第一版项目开发完成,Dev、Prod环境都产生了一定数据。而第二版代码开发过程中,存在新增表、删除表、变更表结构的情况,在第二版开发完成后,需要将最新结构同步到Prod环境。
这与之前执行的prisma/migrate.ts不同,通过prisma migrate diff --from-empty生产的是全量建表结构,仅适用于首次建库时的表结构同步,后续迁移需要另行它法。于是我又添加了一个prod:migrate-sync命令。
package.json 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 { "scripts" : { "dev:migrate" : "npx prisma migrate dev" , "dev:export" : "dotenv -e .env -- node prisma/export.ts" , "dev:import" : "dotenv -e .env -- node prisma/import.ts" , "prod:migrate" : "dotenv -e .env.production -- node prisma/migrate.ts" , "prod:migrate-sync" : "dotenv -e .env.production -- node prisma/migrate-sync.ts" , "prod:export" : "dotenv -e .env.production -- node prisma/export.ts" , "prod:import" : "dotenv -e .env.production -- node prisma/import.ts" , "prod:sync" : "dotenv -e .env.production -- node prisma/sync.ts" } , "dependencies" : { "@libsql/client" : "^0.17.2" , "@prisma/adapter-libsql" : "^7.6.0" , "@prisma/client" : "^7.6.0" } , "devDependencies" : { "dotenv-cli" : "^11.0.0" , "nuxt" : "^4.4.2" , "prisma" : "^7.6.0" } }
主要的思路就是:读取 Prisma 在数据库中创建的_prisma_migrations表记录(其中记录了运行的数据库迁移内容),再与本地的migrations文件夹下的数据库迁移sql脚本对比,将未运行过的迁移文件执行到 Prod 环境数据库中。
prisma/migrate-sync.ts 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 import { createClient } from '@libsql/client' ;import fs from 'fs' ;import path from 'path' ;import crypto from 'crypto' ;import { v4 as uuidv4 } from 'uuid' ;function calculateChecksum (filePath : string string { const fileBuffer = fs.readFileSync (filePath); return crypto.createHash ('sha256' ).update (fileBuffer).digest ('hex' ); } async function syncMigrations ( const encryptionKey = process.env .TURSO_ENCRYPTION_KEY ; const authToken = process.env .TURSO_AUTH_TOKEN ; const dbUrl = process.env .DATABASE_URL !; const migrationsPath = path.join (process.cwd (), 'prisma' , 'migrations' ); const client = createClient ({ url : dbUrl, authToken, encryptionKey }); try { const appliedMigrationsResult = await client.execute ( "SELECT migration_name FROM _prisma_migrations WHERE finished_at IS NOT NULL" ); const appliedNames = new Set (appliedMigrationsResult.rows .map (r =>migration_name as string )); const localMigrations = fs.readdirSync (migrationsPath) .filter (f =>statSync (path.join (migrationsPath, f)).isDirectory ()) .sort (); const pendingMigrations = localMigrations.filter (name =>has (name)); if (pendingMigrations.length === 0 ) { return ; } for (const migrationName of pendingMigrations) { const sqlPath = path.join (migrationsPath, migrationName, 'migration.sql' ); const sql = fs.readFileSync (sqlPath, 'utf8' ); const checksum = calculateChecksum (sqlPath); const migrationId = uuidv4 (); await client.executeMultiple (sql); await client.execute ({ sql : `INSERT INTO _prisma_migrations (id, checksum, finished_at, migration_name, logs, rolled_back_at, started_at, applied_steps_count) VALUES (?, ?, datetime('now'), ?, NULL, NULL, datetime('now'), 1)` , args : [ migrationId, checksum, migrationName ] }); } } catch (e : any ) { console .error ("迁移失败:" , e.message ); process.exit (1 ); } finally { client.close (); } } syncMigrations ();
六、结语 现在项目的数据库已经完全迁移到 SQLite 和 Turso 下了,主包不用再起一台 docker 跑 mysql数据库了,本地开发与调试十分方便,后续还可以考虑结合 Tauri / Electron 等打成桌面端软件,搭配加密的 Turso 数据库就可以安心把数据存在本地了。